这是SemiAnalysis新出的一篇分析讲述,对于最近DeepSeek此次事件的分析,包括中国在成本、真实教化成本、阻塞模子利润率影响方面的率先地位——H100价钱飙升、补贴推理订价、出口不停、多头潜在预防力机制。
春节这几天一直对DeepSeek相等热心,也看到了许多数据。在另一份真实度比较高的讲述中,也看到过对于DeepSeek不可能有5万张H100的说法,这篇讲述也给出了肖似的论断,看来这个说法应该是靠谱的。至于该讲述背面中国政府的补贴计谋,以及DeepSeek是否拿到了这些补贴,咱们还没看到官方的公布。
当天稍晚时,莫斯科四个机场相关临时限制措施已解除。
俄乌在2019年签署为期5年的俄天然气过境乌克兰输往欧洲的协议,协议将于今年年底到期。泽连斯基19日在欧盟峰会期间表示,俄方因该协议获得巨额利润以支持战争,乌方不会将其延长。同日,俄总统普京在年度记者会上说,“经乌克兰向欧洲转运俄天然气的新合同肯定不会有了”,俄方能够承受这一变化。
深度求索的故事席卷全球
深度求索(DeepSeek)的故事在全球引起了颠簸。在昔日的一周里,深度求索成了全球各界唯独的热议话题。咫尺,深度求索的日探访量远超Claude、Perplexity,致使高出了Gemini。
但对于密切热心这一领域的东说念主来说,这其实并非什么“崭新事”,令东说念主注主义是东说念主们对它的豪恣炒作。长期以来,SemiAnalysis一直以为深度求索极具资质,但好意思国寰球此前并不热心。当全寰宇终于运行热心时,却堕入了一种脱离现实的豪恣炒作。几个月来,咱们一直在评论深度求索(每个聚拢皆是例证)。这家公司并不新。
咱们想强调的是,公论风向与上个月比拟发生了逆转。上个月,当规模定律被突破时,有东说念主以为这对英伟达(Nvidia)和GPU不利;如今,又有东说念主说算法修订速渡过快。咱们照旧吊销了这些谬论。
如今的公论以为,深度求索服从极高,咱们不再需要更多诡计资源,何况由于模子的变化,咫尺一切皆存在渊博多余产能。天然杰文斯悖论(Jevonsparadox)也被过度炒作了,但它更接近现实情况。这些模子照旧对H100和H200的订价产生了现实影响,刺激了需求。
深度求索与High-Flyer(幻方)
High-Flyer是一家中国对冲基金,亦然将东说念主工智能应用于交往算法的早期adopters。他们很早就相识到了东说念主工智能在金融领域除外的后劲,以及规模化的要津意旨。因此,他们继续加多GPU的储备。在使用数千个GPU集群对模子进行磨砺后,High-Flyer在2021年出口放胆实施前投资购买了10000个A100GPU,这一举措取得了陈诉。
跟着High-Flyer的发展,他们在2023年5月决定分拆出“深度求索”,标的是更专注地追求东说念主工智能能力的进一步擢升。那时,由于零落营业模式,外部投资者对东说念主工智能兴致寥寥,High-Flyer便自行出资诞生了这家公司。如今,High-Flyer和深度求索往往分享东说念主力和诡计资源。
深度求索如今已发展成为一项庄重且协同的功绩,绝非许多媒体宣称的“副业”。咱们笃信,即便探讨到出口不停成分,他们在GPU上的投资也高出5亿好意思元。
GPU情况
咱们以为迪士尼彩乐园3源码他们领有约50000个HopperGPU,但这并不等同于50000个H100,一些东说念主存在这样的诬陷。英伟达为死守不同划定,坐褥了H100的多种变体(H800、H20),咫尺中国的模子供应商仅能取得H20。需要预防的是,H800的诡计能力与H100沟通,但蚁集带宽较低。
咱们以为深度求索领有约10000个H800和10000个H100。此外,他们还订购了更多H20。在昔日9个月里,英伟达坐褥了高出100万个专供中国的GPU。这些GPU由High-Flyer和深度求索分享,并在一定进程上进行了地舆溜达。它们被用于交往、推理、教化和磋议。如需更具体的详备分析,请参考咱们的《加速器模子》。
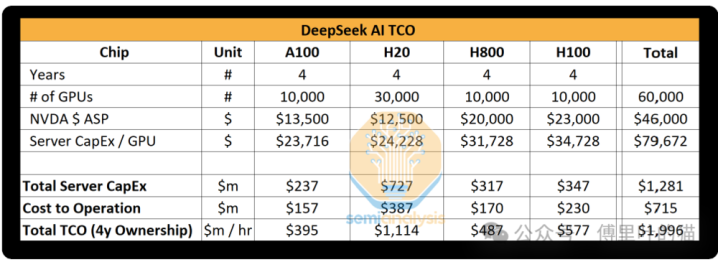
深度求索东说念主工智能的总领有成本
咱们的分析高傲,深度求索的就业器总老本开销接近13亿好意思元,运营这些集群的成本高达7.15亿好意思元。雷同,通盘东说念主工智能实验室和超大规模数据中心为了多样任务(包括磋议和教化),领有的GPU数目比单次教化所需的更多,因为资源蚁集存在一定挑战。X.AI算作一个东说念主工智能实验室比较特有,它通盘的GPU皆蚁集在一个所在。
深度求索只从中国招聘东说念主才,不敬重过往阅历,高度热心能力和肆业欲。他们往往在北京大学和浙江大学等顶尖大学举办招聘行为,招聘告白中致使吹嘘职工能无放胆使用数万个GPU。他们极具竞争力,外传为有后劲的候选东说念主提供高出130万好意思元的年薪,远超中国其他大型科技公司和东说念主工智能实验室,如Moonshot。他们咫尺约有150名职工,且规模还在连忙扩大。岗亭扮装不一定事前设定,招聘东说念主员有一定生动性。
历史标明,资金鼓胀且专注的袖珍初创公司往往能突破极限。深度求索不像谷歌那样官僚主义,由于是自筹资金,他们能连忙将主张付诸实践。不外,和谷歌一样,深度求索(在很猛进程上)运营我方的数据中心,不依赖外部机构或供应商。这为实验开辟了更多空间,使他们能够在通盘这个词时期栈上进行改进。
咱们以为他们是咫尺最佳的“洞开权重”实验室,高出了Meta的Llama名目、Mistral等。
深度求索的成本与性能
本周,深度求索的价钱和服从激励了激越,主要焦点是深度求索V3的“600万好意思元”教化成本。但这是诞妄的。这就好比只看家具物料清单上的某一部分,却将其视为通盘这个词家具的成本。预教化成本只是总成本中很小的一部分。
教化成本
咱们以为预教化成本远非该模子的现实进入。咱们笃信,在公司发展历程中,他们在硬件上的破钞远高于5亿好意思元。为了开发新的架构改进,在模子开发历程中,需要进入渊博资金来测试新主张、新架构想路,并进行消融实验。开发和遣散这些主张需要通盘这个词团队进入渊博东说念主力和GPU诡计时刻。深度求索的要津改进——多头潜在预防力机制(Multi-HeadLatentAttention),就铺张了数月时刻。
论文中提到的600万好意思元成本仅指预教化运行的GPU成本,这只是模子总成本的一部分。研发用度和硬件自己的总领有成本等枢纽部分并未诡计在内。参考一下,Claude3.5Sonnet的教化成本高达数千万好意思元,要是这等于Anthropic所需的一说念成本,他们就不会从谷歌筹集数十亿好意思元,也不会从亚马逊筹集数百亿好意思元了。这是因为他们必须进行实验、提议新架构、采集和算帐数据、支付职工工资等等。
那么深度求索是怎样领有如斯巨大的集群的呢?出口不停的滞后是要津,底下在出口不停部分会详备策画。
缩小差距——V3的性能
V3无疑是一款令东说念主印象真切的模子,但值得预防的是,要明确它是相对于什么而言令东说念主印象真切。许多东说念主将V3与GPT-4o进行比较,并强调V3怎样超越4o的性能。这确乎没错,但GPT-4o于2024年5月发布。东说念主工智能发展连忙,从算法修订的角度来看,2024年5月隔世之感。何况,经过一段时刻后,用更少的诡计资源遣散绝顶或更强的能力,这并不令东说念主不测。推理成本的下落是东说念主工智能越过的一个象征。
深度求索V3的竞争分析
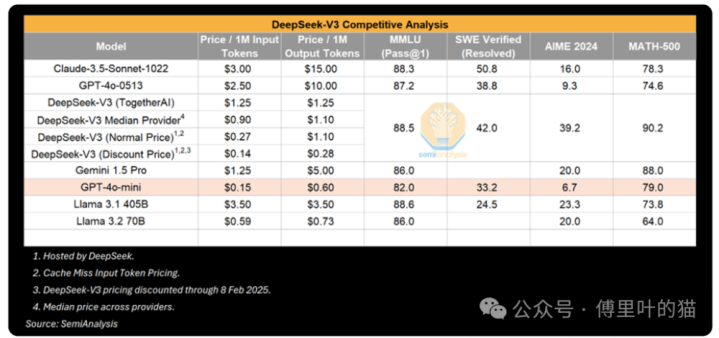
image-20250131202203708
举例,能在条记本电脑上运行的袖珍模子,其性能可与GPT-3相失色,而GPT-3的教化需要超等诡计机,推理则需要多个GPU。换句话说,算法的修订使得用更少的诡计资源来教化和推理具有沟通能力的模子成为可能,这种模式反复出现。此次全寰宇之是以热心,是因为它来自中国的一个实验室。但袖珍模子性能擢升并非崭新事。
到咫尺为止,咱们从这种模式中看到,东说念主工智能实验室为了取得更高的智能水平,在完全金额上的进入越来越多。据规画,算法的越过意味着每年遣散沟通能力所需的诡计资源减少4倍。Anthropic的首席实行官Dario以为,算法订价在野着GPT-3质地发展,成本已下落1200倍。就推理而言,致使不错遣散10倍的修订。
在磋议GPT-4的成本时,咱们也看到了肖似的成本下落趋势,不外处于弧线的更早期阶段。天然跟着时刻推移成本各异的缩小,不可像上头的图表那样通过保握能力不变来解说。在这种情况下,咱们看到算法修订和优化使成本裁减了10倍,同期能力也有所擢升。
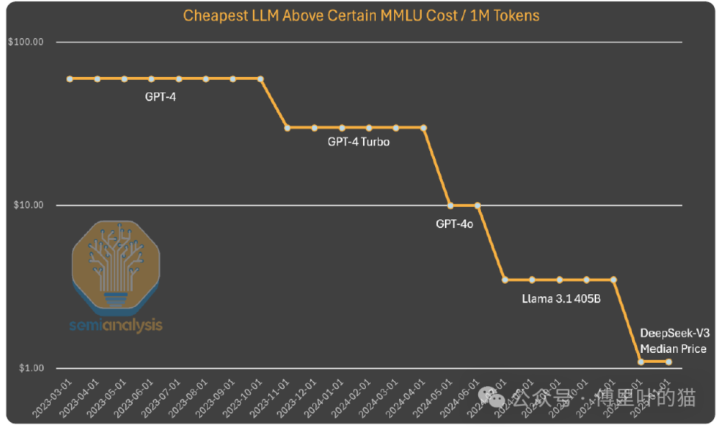
需要明确的是,深度求索的特有之处在于他们率先达到了这样的成本和能力水平。他们发布洞开权重的作念法也很特有,不外之前Mistral和Llama模子也有过肖似举措。深度求索达到了这样的成本水平,但到本年年底,要是成本再下落5倍,也不要感到讶异。
另一方面,R1能够取得与o1绝顶的遣散,而o1直到9月才发布。深度求索是怎样这样快就追逐上的呢?
谜底是,推理是一种新范式,与之前的预教化范式比拟,它的迭代速率更快,且更容易遣散较小诡计量下的显耀擢升,而之前的预教化范式成本越来越高,且难以取得适当的进展。如咱们在讲述中所述,之前的范式依赖于规模定律。
新范式通过在现存模子的教化后阶段,讹诈合成数据生成和强化学习来擢升推理能力,能够以更低的成本遣散更快的越过。较低的进初学槛和易于优化的秉性,使得深度求索能够比往常更快地复制o1的方法。跟着参与者在这种新范式中找到更多延迟方法,咱们揣度遣散沟通能力所需的时刻差距将会扩大。
需要预防的是,R1的论文中并未说起所使用的诡计资源。这并非有时——为教化后的R1生成合成数据需要渊博诡计资源,更无须说强化学习了。咱们并不否定R1是一款相等优秀的模子,能如斯连忙地在推理能力上追逐上令东说念主钦佩。深度求索算作一家中国公司,用更少的资源遣散了追逐,这更是令东说念主齰舌。
但R1提到的一些基准测试也具有误导性。将R1与o1进行比较很难办,因为R1额外莫得说起那些我方不率先的基准测试。天然R1在推感性能上与o1绝顶,但它并非在通盘方针上皆是显然的赢家,在很厚情况下致使不如o1。
咱们还莫得提到o3。o3的能力显然高于R1和o1。事实上,OpenAI最近公布了o3的遣散,其基准测试收货直线上升。“深度学习碰到了瓶颈”是另一种情况。
谷歌的推理模子与R1绝顶
在东说念主们为R1豪恣炒作时,一家市值2.5万亿好意思元的好意思国公司——谷歌,提前一个月发布了一款推理模子GeminiFlash2.0Thinking,且价钱更低。这款模子可供使用,通过API调用时,即使其高下文长度更长,价钱也比R1低廉得多。
在已公布的基准测试中,迪士尼彩票乐园时时彩Flash2.0Thinking的线路优于R1,尽管基准测试并不可证据一说念情况。谷歌只公布了3个基准测试遣散,是以这只是一个不完好的画面。不外,咱们以为谷歌的模子很可靠,在许多方面皆能与R1抗衡,却莫得得到任何炒作。这可能是因为谷歌的市集推论策略野蛮无奇,用户体验也欠安,但也可能是因为R1来自中国,令东说念主感到不测。
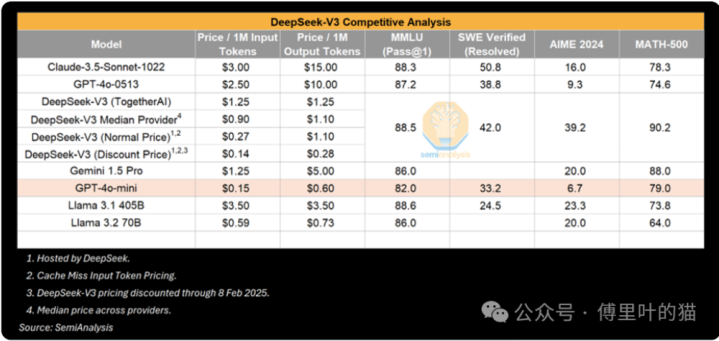
image-20250131202412500
需要明确的是,这些皆无损于深度求索的不凡树立。深度求索算作一家行动连忙、资金鼓胀、东说念主才济济且专注的初创公司,能够在推理模子发布上打败Meta等巨头,值得赞誉。
时期树立
深度求索照旧找到了要津方法,遣散了率先实验室尚未取得的改进。咱们揣度,深度求索公布的任何修订,险些皆会立即被西方实验室效仿。
这些修订有哪些呢?大多数架构上的树立皆与V3策动,V3亦然R1的基础模子。底下详备先容这些改进后果。
教化(预教化和后教化)
深度求索V3大规模应用了前所未有的多令牌预测(MTP)时期,它加多了预防力模块,能够预测接下来的几个令牌,而非单个令牌。这一时期在教化历程中擢升了模子性能,且在推理时可铁心。这是通过算法改进遣散低诡计量下性能擢升的一个程序。
教化历程中还招揽了FP8精度等时期,不外好意思国的率先实验室招揽FP8教化已有一段时刻。
深度求索V3亦然一个羼杂众人模子,即由多个擅长不同领域的小模子构成一个大型模子,这是一种新兴的模子架构。羼杂众人模子靠近的一个难题是怎样细则每个令牌该进入哪个子模子(即“众人”模子)。
深度求索通过实施“门控蚁集”,以一种均衡的方式将令牌路由到允洽的众人模子,且不影响模子性能。这意味着路由服从极高,在教化历程中,相对于通盘这个词模子的规模,每个令牌仅需更动少许参数。这不仅提高了教化服从,还裁减了推理成本。
尽管有东说念主担忧羼杂众人模子(MoE)带来的服从擢升可能并不显耀,省俭下来的成本会连忙被进入到构建更大规模的模子中,导致总体进入不会减少。现实上,MoE提高的服从会加速东说念主工智能的规模化发展。企业皆在专注于扩大模子的诡计规模,并擢升算法服从。达里奥指出,更苍劲的东说念主工智能模子所带来的经济效益十分可不雅。
就R1而言,它极地面受益于苍劲的基础模子(V3),部分原因在于强化学习(RL)。强化学习主要聚焦两个方面:花式表率(确保输出连贯)以及灵验性和无害性(确保模子实用)。在基于合成数据集对模子进行微调的历程中,R1的推理能力得以擢升,这与o1的情况肖似。
需要预防的是,R1的论文中并未说起诡计资源的使用情况,因为说起所用的诡计资源会透露他们现实领有的GPU数目比对外宣称的更多。如斯大规模的强化学习,尤其是在生成合成数据时,需要渊博的诡计资源,正如咱们在对于规模定律的著作中所提到的。
此外,深度求索使用的部分数据似乎来自OpenAI的模子,咱们以为这可能会对输出数据索取策动计谋产生影响。从就业要求来看,这种数据索取行动照旧属于违法。将来,一种肖似“了解你的客户”(KYC)的机制可能会出现,以阻绝此类数据索取行动。
多头潜在预防力机制(MLA)
MLA是深度求索大幅裁减推理成本的要津改进。它能将每次查询所需的KV缓存减少约90%(相较于递次预防力机制)。KV缓存是Transformer模子中的一种内存机制,用于存储对话高下文数据,减少不必要的诡计。
正如咱们在规模定律著作中所策画的,跟着对话高下文的加多,KV缓存也会增大,从而带来显耀的内存放胆问题。大幅减少每次查询所需的KV缓存,意味着每次查询所需的硬件资源减少,进而裁减成本。不外,咱们以为深度求索以成本价提供推理就业是为了获取市集份额,现实上并未盈利。
谷歌的GeminiFlash2.0Thinking价钱更低,何况谷歌不太可能以成本价提供就业。MLA尤其引起了好意思国许多率先实验室的热心,它于2024年5月随深度求索V2发布。由于H20相较于H100具有更高的内存带宽和容量,深度求索在使用H20进行推理责任负载时服从更高。他们还文告与华为建立配合干系,但咫尺在昇腾诡计方面的配合后果尚不显然。
咱们以为,MLA对利润率的影响最为值得热心,这对通盘这个词生态系统意旨紧要。以下是咱们对将来东说念主工智能行业订价结构的揣度,同期详备融会了为何以为深度求索在补贴价钱,以及杰文斯悖论初现脉络的原因。此外,咱们还将探讨出口不停的影响、中国政府可能对深度求索日益增长的主导地位作念出的反应等问题。
对利润率的平常影响
在利润率方面,有一个要津发现:R1并非从时期层面平缓了o1的进展,而是以更低的价钱遣散了绝顶的能力。这在实质上是合理的,咫尺咱们引入一个对于将来订价机制的框架。
擢升能力能够带来更高的利润率。这与半导体制造行业的发展极为相似,台积电率先进入新节点(遣散新能力)时,由于创造出了前所未有的家具,从而取得了显耀的订价权。
其他过时的竞争敌手(如三星、英特尔)为了在性价比上达到均衡,会以低于率先者的价钱提供家具。对芯片制造商(在此类比为东说念主工智能实验室)而言,红运的是他们不错调遣产能。要是在新模子上能够遣散更高的性价比,他们就不错将产能滚动到新模子的坐褥上。旧型号仍会得到解救,但供应量会减少。这与现时东说念主工智能实验室的现实情况以及半导体制造行业的规章高度吻合。
能力的商品化与对更强能力的不懈追求
这粗略等于能力竞争的将来走向。率先达到新的能力层级,将取得可不雅的订价溢价;而那些连忙跟上的参与者,只可取得浮浅利润。处于能力层级下贱的家具,要是能中意特定用例的需求,仍会络续存在。每一代能够追逐上率先能力的参与者将越来越少。
咱们见证的是,R1达到了率先的能力水平,却以零利润率订价。这种巨大的价钱各异激励了一个问题:为什么OpenAI的家具如斯上流?这是因为他们基于最前沿的时期订价,并享受着前沿时期带来的溢价。
咱们以为,将来的发展将比率先的芯片制造动态更快。追逐最新的能力意味着握续的订价权(举例ChatGPTPro),而过时的能力则意味着更低的订价,此时利润主要来源于为令牌就业的基础身手。
鉴于咱们正处于快速的时期周期中,为追求率先的能力,家具更新换代的速率也会加速。惟有你能继续拓展能力,开发出创造价值的新功能,就理当取得订价权;不然,在洞开模子市集中,你很快就会靠近家具同质化的问题。
咱们以为,在这种配景下,东说念主们对现时发生的事情存在根人道的诬陷。咱们所描绘的情况肖似于超高速发展的芯片制造行业,这是寰宇上老本密集度最高的行业。全球莫得哪个行业在研发上的进入比芯片制造行业更多,但与之最相似的现实情况却被以为对解救模子公司的芯片产业不利。
将东说念主工智能令牌与杰文斯悖论比拟较,会发现二者有着真切的历史相似性。起原,东说念主们并不细则晶体管是否能够继续缩小尺寸;而当这一趋势明确后,通盘这个词行业便发愤于将互补金属氧化物半导体(CMOS)时期的尺寸缩小到极致,并在此基础上构建出多样重邀功能。
咱们咫尺正处于整合多种想维链(CoT)模子和能力的初期阶段,就像最初对晶体管进行规模化发展一样。天然从时期越过的角度来看,这可能是一个飘荡时期,但对英伟达来说却是故意的。
深度求索补贴推理利润率
现实情况是,市集在寻找一个根由,而他们礼聘了这一丝。要是深度求索舒畅接受零利润率致使负利润率,那么他们的家具价钱可能会如斯之低,但显然,提供前沿令牌就业的价钱弹性点要高得多。探讨到深度求索正在进行新一轮融资,他们有动机这样作念。
深度求索在推理领域的要津切入点上,突破了OpenAI的率先利润率。这种率先地位会握续下去吗?咱们以为不会——毕竟一个洞开实验室展示出了阻塞实验室的能力。尽管这一丝至关枢纽,但咱们仍需预防,深度求索是一个快速跟班者。
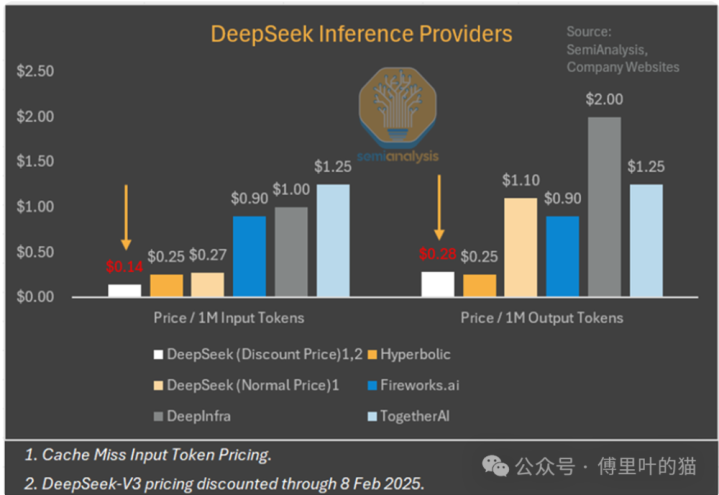
image-20250131202928893
咱们确乎以为,一个更苍劲的洞开实验室(深度求索咫尺是其中的杰出人物)对新兴云就业提供商和就业供应商来说诟谇常故意的。岂论是洞开模子照旧阻塞模子,诡计资源的蚁集化仍然很枢纽,但要是基于诡计资源构建的表层就业免费提供家具,那么诡计资源的价值就有可能擢升。更多的资金会流向诡计资源领域,而非阻塞模子供应商,这意味着开销更多地流向了硬件领域。软件企业也能从中获益匪浅。
H100价钱飙升:杰文斯悖论的体现
咱们照旧看到了这一表面的早期迹象。自V3和R1发布以来,AWS多个地区的H100GPU价钱高涨,H200也更难获取。
V3发布后,H100价钱大幅高涨,因为GPU运行以更高的费率遣散货币化。更低的成本遣散更强的智能意味着更多的需求。这与前几个月H100现货价钱的低迷变成了显明对比。
出口不停的影响、深度求索与中国政府
从地缘政事的角度来看,深度求索与西方实验室在能力方面的对比,以及出口不停的影响,皆值得深入想考。咫尺照旧实施的东说念主工智能扩散不停措施,咱们以为不会取消。
有音讯称,出口不停因深度求索的发展而失败,但这是对出口不停机制的诬陷。最初,H100被绝交出口,而诡计能力邻近(但带宽受限)的H800被允许出口;随后,H800也被绝交,咫尺仅允许H20出口。咱们在《加速器模子》中提到,尽管需求巨大,但英伟达在1月份取消了渊博H20订单,这可能预示着好意思国行将出台新的禁令。
在这些法律的实施历程中存在脱期期,深度求索很可能在这段时刻内渊博囤积所需芯片。需要预防的是,H100自愿布以来就被绝交出口。从这个角度来看,出口不停未能完全放胆高性能芯片的供应。出口不停的主义并非完全割断中国获取芯片的渠说念,而是对通盘这个词生态系统进行严格放胆,意味着放胆数十万致使数百万芯片的供应,而不单是是数万个。
可是,咱们揣度将来H20也将被绝交出口,这将进一步放胆深度求索获取芯片的能力。
而他们对芯片的需求十分顾惜。
深度求索的产能放胆
深度求索难以中意急剧增长的需求。尽管他们领有寰宇上最出色的推理时期之一,但进行架构研发、教化模子,与为数千万用户提供可靠就业是天差地远的挑战。深度求索的注册就业时常关闭,即便洞开注册时,R1的反应速率也极慢(不外奥密的用户体验瞎想狡饰了这一问题)。
咱们本月看到的模子受之前出口不停的影响,存在一定滞后性。跟着时刻推移,深度求索在延迟模子和就业能力方面将靠近越来越大的困难。延迟能力接于面前,中国也深知这一丝。
在与深度求索的首席实行官兼首创东说念主会面后的第二天,中国银行文告将来5年将为东说念主工智能产业链提供1400亿好意思元(1万亿元东说念主民币)的补贴。该补贴的明确标的是助力中国在科技领域遣散完全自主,涵盖基础磋议、产业应用和开发等方面。东说念主工智能与机器东说念主、生物时期和新材料是要点热心领域。此外,补贴还包括诡计基础身手和数据中心修复,以及为第一代时期开采提供保障和风险解决解救。
咱们以为,将来出口不停的影响将愈加显耀:算法和硬件皆将继续越过,好意思国的实验室能够讹诈这些改进后果进行延迟,达到中国难以企及的高度。天然中国可能仍会推出与好意思国实验室相失色的模子,但将络续处于追逐地位。